Monitoring Docker Swarm with cAdvisor, InfluxDB and Grafana
View CodeMonitoring is essential to know the state of our running applications. When you are running your applications in a scalable environment like Docker Swarm, you need a scalable monitoring solution as well. In this article, we will setup just that.
We will install cAdvisor agents in each nodes to collect host and container metrics. We will save these time-series metrics in InfluxDB. We will use Grafana to setup dashboards for this metrics. All these tools are open-source and can be deployed as a container.
We will use the Docker Swarm Mode to build the cluster and deploy these services as a stack. This allows for a dynamic setup for monitoring. Once we deploy this stack in a swarm, any new nodes joining the swarm will be automatically monitored. All the files used for this project can be found here.
Tools Overview
There are plenty of options for monitoring solutions. We are using open-source and container friendly services to build our stack. Our stack comprises of the following services.
cAdvisor
cAdvisor collects the metric from the host and docker containers. It is deployed as a docker image with shared volumes to docker socket and root file system of the host. cAdvisor pushed these metrics to a bunch of time-series database including InfluxDB, Prometheus, etc. It even has a web UI that shows graphs of the metrics collected.
InfluxDB
Scalable datastore for metrics, events, and real-time analytics
InfluxDB is open source time series database. You can save numeric value metrics with tags. It supports a SQL like query language to query for data. The tags let us filter data for a specific host and even a spefic container.
Grafana
Grafana is an open source, feature rich metrics dashboard and graph editor for Graphite, Elasticsearch, OpenTSDB, Prometheus and InfluxDB.
Grafana is a popular graphing tool that lets you build dashboards with data from Graphite, Elasticsearch, OpenTSDB, Prometheus and, of course, InfluxDB. From version 4 of grafana, you can also setup alerts based on query conditions. We will setup dashboard that can be drilled down to specific host and service.
Docker Swarm Mode
Docker introduced Swarm Mode from version 1.12.0. This allows us to easily create and manage swarm of multiple hosts. The swarm mode has the key-value store for service discovery and orchestration capability in-built. You can join hosts into a swarm as a manager or a worker. Generally, manager handles the orchestration part and workers are used to run the containers. Since this is for demostration, we will run InfluxDB and Grafana in the manager itself.
Swarm Mode has an interesting feature called router mesh. This acts as virtual load balancer. Let’s say that we have 10 containers running across 5 nodes and they listen to the port 80. Now, if you access the port 80 of any of the hosts. You will directed to any one of the 10 running instance, even the instances that are not even in that particular host. So you can publish the IP of any of the nodes and the requests will be automatically load balanced between all the 10 containers.
To follow along with the demonstration, you need to have the following prerequisites:
Docker: version >= 17.10 CE, to support Docker Compose File version 3 and Swarm Mode.Docker Machine: version >= 0.12Docker Compose: version >= 1.16, to support Docker Compose file version 3
We will be creating 3 local VMs to form the swarm using the Virtualbox plugin of docker-machine. For this, you need to have Virtualbox installed in the system. You may also deploy the nodes in cloud services using different plugins. The steps after creating in the VMs are same for all the plugins. You can read more about docker-machine here.
We will using the default options to create the VMs. To know more about the options available, check here. We will create a host named manager that acts as the manager for the swarm and two hosts agent1 and agent2 to act as the workers. You may create as many nodes as you want. Just repeat the commands with the host names changed. To create the VMs, execute the follwing commands.
docker-machine create manager
docker-machine create agent1
docker-machine create agent2These commands may take some time. After creating the VMS, the output for the command docker-machine ls should look something like this.
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
agent1 - virtualbox Running tcp://192.168.99.101:2376 v17.03.1-ce
agent2 - virtualbox Running tcp://192.168.99.102:2376 v17.03.1-ce
manager - virtualbox Running tcp://192.168.99.100:2376 v17.03.1-ce Now you have to switch context to use the docker engine in the manager. We will be doing the rest of the demostration in the docker engine of the manager and NOT in our local system. To do this, run the following command.
eval `docker-machine env manager`We have now switched over to the docker engine in manager. We will initialize the swarm with manager acting as its manager. We have to mention the IP which will be published for other nodes to join the swarm. We will use the IP of manager for this. The command, docker-machine ip manager will get you this. So, to create the swarm, run the following command.
docker swarm init --advertise-addr `docker-machine ip manager`Now, we need to add the two workers to this swarm. To do this, we need to pass a Join Token and the IP published when the swarm was created. To get the token for joining the swarm as a worker, you can run the command docker swarm join-token -q worker. As before, docker-machine ip manager will get the IP for joining and the default port for this is 2377. We could join the swarm by changing the context to each of the workers, but it is easier to run the commands as via SSH. To join workers to the swarm, run the following commands.
docker-machine ssh agent1 docker swarm join --token `docker swarm join-token -q worker` `docker-machine ip manager`:2377
docker-machine ssh agent2 docker swarm join --token `docker swarm join-token -q worker` `docker-machine ip manager`:2377You can see the nodes in the swarm with the command docker node ls. Once the workers are added the output of the command must look something like this.
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
3j231njh03spl0j8h67z069cy * manager Ready Active Leader
muxpteij6aldkixnl31f0asar agent1 Ready Active
y2gstaqpqix1exz09nyjn8z41 agent2 Ready ActiveDocker Stack
With the version 3 of docker-compose file, we can define the entire stack with the deployment strategy with one file and deploy it with one command. The main difference between version 2 and 3 of docker-compose file is the introduction of the deploy parameter for each service. This parameter will define where and how you want the containers to be deployed. The docker-compose file for the monitoring file is given below.
version: '3'
services:
influx:
image: influxdb
volumes:
- influx:/var/lib/influxdb
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
grafana:
image: grafana/grafana
ports:
- 0.0.0.0:80:3000
volumes:
- grafana:/var/lib/grafana
depends_on:
- influx
deploy:
replicas: 1
placement:
constraints:
- node.role == manager
cadvisor:
image: google/cadvisor
hostname: '{{.Node.Hostname}}'
command: -logtostderr -docker_only -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influx:8086
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
depends_on:
- influx
deploy:
mode: global
volumes:
influx:
driver: local
grafana:
driver: localWe will start by saying that we are using the version 3 of docker-compose file. We have following 3 services in the stack.
influx
This uses the influxdb image and for persistent storage, we are creating a volume named influx that is mounted to the /var/lib/influxdb folder in the container. In the deploy key, we are saying that we need one copy of InfluxDB which we will place in the manager. Since we are using docker engine in the manager, we can execute commands to this container from here itself. As both the other services needs influxDB to run, we will add a depends_on key to other services with influx in it.
grafana
We will use the image grafana/grafana and expose the port 3000 of the container to port 80 of the host. The router mesh feature will then let us access grafana from port 80 of any host in the swarm. We have another volume named grafana mounted to /var/lib/grafana in the container for persistent data. As before, we also deploy one copy of grafana in the manager.
cadvisor
cAdvisor service has much more configuration required than the other services. To know more, check this out. The hostname key is a tricky one. We intend to put one agent in each node of the swarm and this container will collect all metrics from the node and the containers running in it. When cAdvisor send metrics to InfluxDB, it send it with a tag machine that contains the hostname of cAdvisor container. We need to match it with the hostname of the node running it. Docker stacks allows templating in naming. We have named the containers with the ID of the node running it so that we know where the metric is coming from. The is done by the value '{{.Node.Hostname}}'.
We also add some command line parameters to cadvisor. The logtostderr redirects the logs generated by cadvsior to stderr, which makes it easy to debug. The docker_only flag says that we are only interested in docker based containers. The next three parameters defines where you want metrics to be pushed for storage. We are asking cAdvisor to push the metrics to cadvisor database in InfluxDB server listening at influx:8086. This will send the metrics to the influx service in the stack. In a stack, all ports are exposed and you don’t have to specifically mention them.
cAdvisor need the volumes mentioned in the file to collect the metrics from the host and docker system. We use the mode global for deploy in cadvisor service. This will ensure that exactly one instance of cadvisor service will be run in each node of the swarm.
Finally, at the end of the file, we have the volumes key with the influx and grafana volumes. As we are using the local driver for both the volumes, the volumes will be stored in the manager.
To deploy this stack, save the above file as docker-stack.yml and run the following command.
docker stack deploy -c docker-stack.yml monitorThis will start the services in the stack which is named monitor. This might take some time the first time as the nodes have to download the images. Also, you need to create the database named cadvisor in InfluxDB to store the metrics.
docker exec `docker ps | grep -i influx | awk '{print $1}'` influx -execute 'CREATE DATABASE cadvisor'This command might fail saying that the influx container doesn’t exist. This is beacuse the container is not yet ready. Wait for some time and run it again. We are able to run the commands in the influx service beacuse it is running in manager and we are using its docker engine. To find the ID of InfluxDB container, you can use the command docker ps | grep -i influx | awk '{print $1}' and we are executing the command influx -execute 'CREATE DATABASE cadvisor' to create the new database names cadvisor.
To see the services in the stack, you can use the command docker stack services monitor, the output of the command will look like this.
ID NAME MODE REPLICAS IMAGE
0fru8w12pqdx monitor_influx replicated 1/1 influxdb:latest
m4r34h5ho984 monitor_grafana replicated 1/1 grafana/grafana:latest
s1yeap330m7e monitor_cadvisor global 3/3 google/cadvisor:latestYou can see the running containers in the stack with the command docker stack ps monitor. Its output will look like this.
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
n7kobaozqzj6 monitor_cadvisor.y78ac29r904m8uy6hxffb7uvn google/cadvisor:latest agent2 Running Running about a minute ago
1nsispop3hsu monitor_cadvisor.z52c9vloiutl5dbuj5lnykzvl google/cadvisor:latest agent1 Running Running about a minute ago
9n6djc80mamd monitor_cadvisor.qn82bfj5cpin2cpmx9qv1j56s google/cadvisor:latest manager Running Running about a minute ago
hyr8piriwa0x monitor_grafana.1 grafana/grafana:latest manager Running Running about a minute ago
zk7u8g73ko5w monitor_influx.1 influxdb:latest manager Running Running about a minute agoSetting Up Grafana
Once the services are deployed, you can open up grafana with the IP of any node in the swarm. We will open the IP of manager with the following command.
open http://`docker-machine ip manager`By default, use the username admin and password admin to login to grafana. The first thing to do in grafana is to add InfluxDB as the datasource. In the home page, there must be a Create your first data source link, click that. If the link is not visible, you can select Data Sources from menu and choosing Add data source from there. This will give you the form to add a new Data Source.
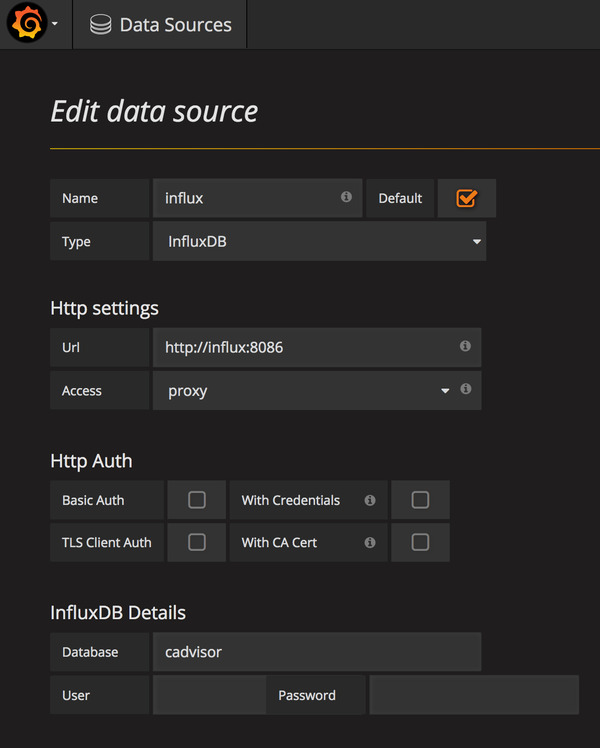 Add Data Source in Grafana
Add Data Source in Grafana
You can give any name for the source. Check the default box, so that you won’t have to mention the data source everywhere. Choose the type as InfluxDB. Now, the URL is http://influx:8086 and Access is proxy. This will point to the port listened by the InfluxDb container. Finally give the Database as cadvisor and click the Save and Test button. This should give the message Data source is working.
In the github repository, I have added the file dashboard.json, that can be imported to Grafana. This will provide a dashboard that monitors the systems and the containers running in the swarm. We will import the dashboard now and talk about it in the next section. From the menu, hover over Dashboards and select Import Option. Click the Upload .json file button and choose the dashboard.json file. Select the data source and click the Import button to import this dashboard.
Grafana Dashboard
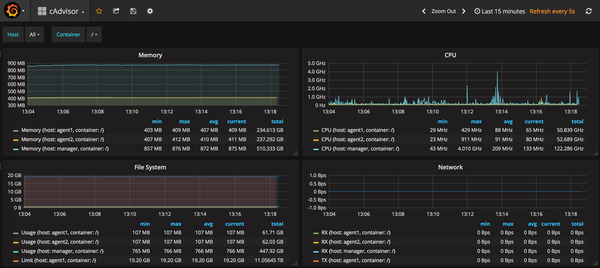 Grafana Dashboard
Grafana Dashboard
The dashboard imported to Grafana will monitor the host and containers in the swarm. You can drill down to host level and even to the container level in each host. To be able to do this, we are using two variables. To add variables to Grafana dashboard, we use the templating feature. To know more about templating with InfluxDB, check here. There are two varibles, host to select the node and container to select the container. To see the variables, select Settings from dashboard page and choose Templating.
The first variable is host and this provide the option to select the node and drill down to its metrics. When cAdvisor sends metrics to InfluxDB, it also includes some tags, which we will use to filter the metrics. There is a tag named machine that shows the hostname of the cAdvisor instance. In this case, it will match the ID of the hosts in swarm. To get the values in the tag, we use show tag values with key = "machine" as the query.
The second variable is container and this is to further drill down to the container level metrics. There is a tag named container_name that contains the container name. We also need to only get the values based on the value of host variables. So, the query is show tag values with key = "container_name" WHERE machine =~ /^$host$/. This will fetch the containers which is running in the node selected by the host variable.
The container name will look something like this, monitor_cadvisor.y78ac29r904m8uy6hxffb7uvn.3j231njh03spl0j8h67z069cy. However, we are only interested in monitor_cadvisor part of it, till the first period. If there are multiple instance of the same service, we need seperate lines. To filter the portion until first period, we use /([^.]+)/ as the regex.
Now that we have set up the varibles, we can use it in the graphs. We will discuss about Memory graph and the rest are similar. The memory values is present in the memory_usage series in InfluxDB, so the query starts with SELECT "value" FROM "memory_usage".
Now we add the filters with the WHERE keyword. The first condition is that machine is equal to host variable. That is given by "machine" =~ /^$host$/. The second condition is that container_name starts with the container variable. We use the starts with operator here because we have filtered the container variable until first period. This is given by "container_name" =~ /^$container$*/. The final condition is to match the time interval selected in grafana dashboard, $timeFilter. The query is now SELECT "value" FROM "memory_usage" WHERE "container_name" =~ /^$container$*/ AND "machine" =~ /^$host$/ AND $timeFilter.
As we need seperate lines for different hosts and container, you need to group the data based on the machine and container_name tags. So now the entire query becomes, SELECT "value" FROM "memory_usage" WHERE "container_name" =~ /^$container$*/ AND "machine" =~ /^$host$/ AND $timeFilter GROUP BY "machine", "container_name".
We have also applied the alias for this query as Memory {host: $tag_machine, container: $tag_container_name}. Here, $tag_machine will be replaced by the value in machine tag and tag_container_name will be replaced by the value in container_name tag. The rest of the graphs are similar. Only the series name changes. You can also create alerts for these metrics from inside Grafana. For more about Alerting, check here.
Conclusion
In this article, we were able to set up scalable monitoring solution for Docker Swarm, that automatically monitors all hosts and containers running in the swarm. While doing this, we became familiar with popular open-source tools like Grafana, InfluxDB and cAdvisor.
Once you are done with the demonstration, you can remove the stack with command,
docker stack rm monitorIf you are done with the VMs created for the demo, you can stop and remove then with the following commands,
docker-machine stop manager agent1 agent2
docker-machine rm -f manager agent1 agent2